
Postgres Professional продолжает публиковать книги о возможностях СУБД PostgreSQL. В этот раз представляем учебное пособие для тех, кто хочет стать маэстро в управлении базами данных.
Postgres Professional продолжает публиковать книги о возможностях СУБД PostgreSQL. В этот раз представляем учебное пособие для тех, кто хочет стать маэстро в управлении базами данных.

Хочу рассказать, как спроектированы распределённые вычисления в ClickHouse. Вы узнаете, на что влияет схема кластера (и на что не влияет). Расскажу, как можно на ровном месте создать себе проблему при помощи всего одной таблицы Kafka и нескольких матвьюх. Поделюсь опытом про дебаг и оптимизацию SELECT-запросов к Distributed таблицам: поизучаем планы выполнения и поэксперементируем с настройками в блоке SETTINGS.

В машинном обучении SQL используют для анализа весов, поиска аномалий, сравнения моделей и визуализации их логики. Он помогает определить значимость признаков, заметить переобучение и оценить работу модели.
В статье разберём, как хранить и извлекать веса, вычислять ключевые метрики и строить графики.

Выбор подходящей системы управления базами данных (СУБД) — важнейшая задача при проектировании программных систем. Разработчики и архитекторы учитывают множество факторов: модель данных (реляционная или NoSQL), поддержку транзакций, масштабируемость, требования к согласованности и многого другое. Одним из ключевых архитектурных аспектов, влияющих на эффективность и надежность системы, является модель репликации данных. Репликация означает поддержание копий одних и тех же данных на нескольких узлах (серверах), соединённых по сети.
Зачем это нужно? Репликация позволяет: во-первых, держать данные ближе к пользователям (уменьшая задержку при запросах); во-вторых, продолжать работу системы даже при сбое отдельных узлов (повышая доступность); в-третьих, масштабировать систему, увеличивая число узлов для обслуживания запросов на чтение (повышая пропускную способность).
Однако реализация репликации сопряжена с серьёзными архитектурными компромиссами. Согласно теореме CAP, в распределённой системе невозможно одновременно гарантировать все три свойства: консистентность данных, доступность сервиса и устойчивость к разделению сети. При возникновении сетевых сбоев (разбиении на изолированные сегменты) системе приходится жертвовать либо мгновенной согласованностью данных, либо доступностью части узлов. Поэтому разные СУБД делают разные выборы в этих компромиссах. Архитектурная модель репликации, лежащая в основе СУБД, определяет, как база данных достигает (или не достигает) консистентности, доступности и отказоустойчивости. Понимание этих различий крайне важно для архитекторов и разработчиков: зная поведение репликации, вы сможете выбрать такую СУБД, которая лучше соответствует требованиям вашего проекта по масштабу, геораспределенности, допустимой задержке и устойчивости к сбоям.

В этой челлендж-серии статей попробуем использовать PostgreSQL как среду для решения задач Advent of Code 2024.
Возможно, SQL не самый подходящий для этого язык, зато мы рассмотрим его различные возможности, о которых вы могли и не подозревать.
Применяем простые операции над массивами, чтобы определить связность графов.

Как экономить до 90% оперативной памяти при загрузке pandas DataFrame из базы данных?
Сравним различные способы выгрузки данных и найдем метод для снижения потребления оперативной памяти.
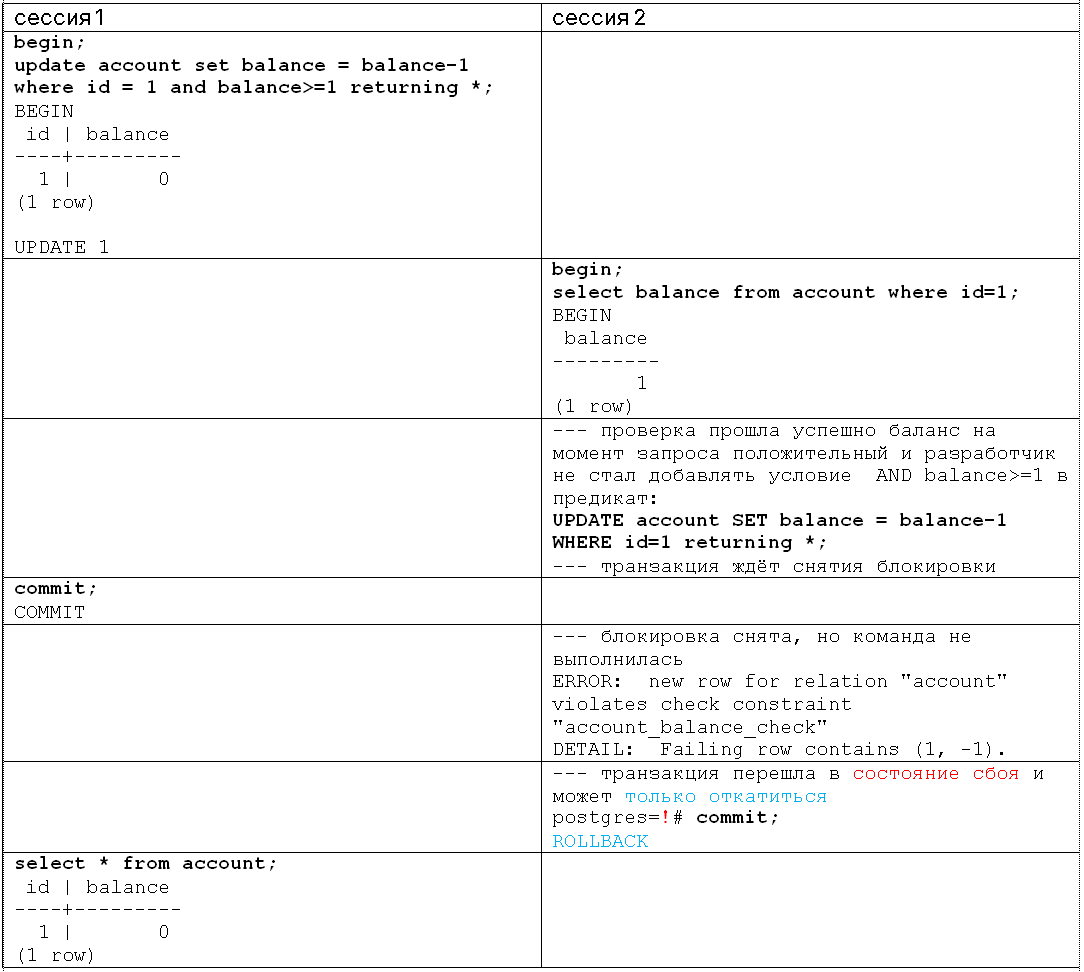
В распределённых базах данных YDB, CockroachDB по умолчанию используется уровень изоляции SERIALIZABLE. В PostgreSQL, Oracle Database, MySQL по умолчанию используется READ COMMITED. В стандарте SQL указаны только три аномалии. В статье приводится пример аномалии потерянного обновления в задаче "списания средств" и рассматривается, почему уровень READ COMMITED и ограничения целостности достаточны для решения задачи.
Если с данными (строками таблиц) работает одна сессия в базе данных, то разницы между уровнями изоляции транзакций нет, так как нет транзакций, от которых нужно изолироваться. Если есть несколько транзакций, которые пересекаются во времени, то нужно обращать внимание на то, что параллельно с теми же данными работают другие транзакции. Другими словами, учитывать особенности (феномены, аномалии) "конкурентного доступа".

Это вторая часть серии вопросов для подготовки к интервью по SQL. В ней мы обсудим еще 15 наиболее часто встречающихся вопросов, которые вам могут задать на собеседовании.

Исторически платформа lsFusion долгое время разрабатывалась как платформа разработки бизнес-приложений. В современном же мире грань между бизнес-приложениями и веб-приложениями постепенно стирается, соответственно одной из основных целей последних версий lsFusion стало превращение ее в том числе в платформу разработки веб-приложений.
Для достижения этой цели в 5-й версии (как и в 4-й) гораздо больше внимания было уделено UI/UX, а не бизнес-логике. Так, существенно расширились возможности кастомизации пользовательского интерфейса, осовременился дизайн, асинхронность большинства процессов вышла на новый уровень и вообще произошло значительное улучшение многих метрик, критически важных при разработке любого современного веб-приложению. Впрочем, обо всем по порядку.

По прогнозу Gartner, запросы на естественном языке вытеснят SQL уже в 2026 году. Возможно, прогноз Gartner чересчур оптимистичный, но если они и ошибаются, то только в сроках — сам переход на естественный язык в работе с БД неизбежен.

Привет, Хабр!
Сегодня я хочу поговорить о том, без чего не обходится практически ни один серьёзный проект с большими данными (да и с не слишком большими тоже) — о промежуточных витринах (или более привычно – staging, core, data mart).

Привет, Хабр!
Сегодня поговорим про RFM-анализ на SQL. Простыми словами: RFM-анализ — это способ понять, насколько ценные у тебя пользователи.

Go. PgxWrappy как решение всех проблем PgX. Если вы сталкивались с неудобным сканом в структуры посредством PgX на Go, то гляньте эту либу. Она решает все проблемы сканинга.
В мире разработки и работы с базами данных Bloom-фильтры – это мощный, но малоизвестный инструмент, который может значительно ускорить выполнение запросов и снизить нагрузку на систему. Однако, несмотря на их потенциал, многие разработчики даже не знают, что Postgres поддерживает Bloom-фильтры "из коробки" (функциональность Bloom-фильтров доступна сразу после установки Postgres, при включении соответствующего расширения) через расширение bloom.
Bloom-фильтры особенно полезны в ситуациях, когда нужно быстро проверить, принадлежит ли элемент к множеству, или когда требуется оптимизировать запросы с несколькими условиями. Например, они могут ускорить JOIN-запросы, поиск по нескольким столбцам или агрегатные функции.
В этой статье мы разберем, что такое Bloom-фильтры, как они работают в Postgres, и в каких случаях их использование может быть полезным. Мы также рассмотрим практические примеры и покажем, как Bloom-фильтры могут помочь в оптимизации запросов.

В этой челлендж-серии статей попробуем использовать PostgreSQL как среду для решения задач Advent of Code 2024.
Возможно, SQL не самый подходящий для этого язык, зато мы рассмотрим его различные возможности, о которых вы могли и не подозревать.
Используем оконные функции, чтобы вычислить "третью производную".
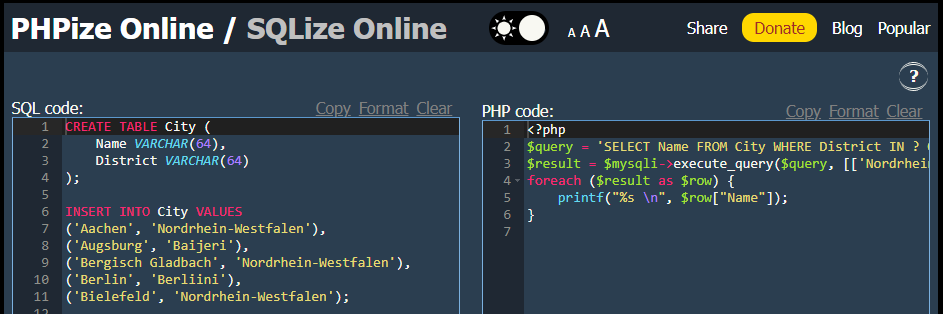
История началась чуть больше двух лет назад. В силу обстоятельств я на две недели остался заперт дома и проводил большую часть времения в компании ноутбука. Чтобы отвлечься рефрешил странички StackOverflow и Тостера в поиске интересных вопросов где бы пригодились мои знания. Ккак знают завсегдатаи этих сайтов у вопрошающих требуют "покажи свой код" да и при ответе считается хорошим тоном публикация работающего ответа. В случае PHP или SQL все просто вот https://dbfiddle.uk вот https://onlinephp.io все просто и понятно - написал код лил запрос опубликовал ссылку и готово.
Оказалась что есть большая категория на стыке PHP и MySQL. Как быть хотелось бы и в этом случае опубликовать ссылку на то и другое и желательно на одном сайте. Вечер был убит на поиски достойного кандидата - безрезультатно.
Следующий день - все по написанному:
- Отрицание - не может быть что никто такого еще не сделал
- Гнев, Торг, Депрессия - пропущу
- Принятие - похоже придется делать самому
Планирование:
- фронт: тяп ляп HTML/CSS пару строк Javascript, даже JQuery не понадобился :)

Таблица справочник, которая является медленно изменяющейся и также генерирует DAG.
В статье рассказывается как можно хранить бизнес-метрики и собирать их через DAG.

Cтремительное развитие социальных медиа, онлайн-платформ, а также огромное количество текстов, создаваемых и обменивающихся пользователями каждый день, делают необходимым понимание того, какие эмоции и оттенки содержатся в текстовых данных. В этом контексте анализ сентимента — определение эмоциональной тональности текста (положительной, отрицательной или нейтральной) — становится ключевым инструментом для бизнеса, маркетинга, общественной деятельности и даже политики.
Анализ сентимента позволит нам, к примеру выявить, какие аспекты вашего продукта вызывают положительные отзывы, а какие — негативные. Такая информация поможет вам улучшить продукт, повысить удовлетворенность клиентов и, как следствие, увеличить прибыль.
Не буду вдаваться в подробности о том, откуда берутся миллионы временных серий и почему они умудряются изменяться еженедельно. Просто возникла задача еженедельно сделать прогноз на 2-8 недель по паре миллионов временных серий. Причем не просто прогноз, а с кроссвалидацией и выбором наиболее оптимальной модели (ARIMA, нейронная сеть, и т.п.).
Имеется свыше терабайта исходных данных и достаточно сложные алгоритмы трансформации и чистки данных. Чтобы не гонять большие массивы данных по сети решено было реализовать прототип на одном сервере.