

Исповедь о том как принес в проект проблему, которую так и не устранил в течение долгого времени.
Осторожно! Статья может вызвать обострение профессиональных заболеваний вплоть до боли ниже поясницы.
Исповедь о том как принес в проект проблему, которую так и не устранил в течение долгого времени.
Осторожно! Статья может вызвать обострение профессиональных заболеваний вплоть до боли ниже поясницы.

Привет, Хабр! Меня зовут Евгений Абрамкин, я руководитель поддержки третьего уровня в направлении омниканальных решений Лиги Цифровой Экономики. Моя команда — последняя «инстанция» во флоу по решению инцидентов. Мы пишем доработки и фиксы, чтобы победить проблему клиента, а также можем предоставить оптимальную конфигурацию для системы, которая передана на эксплуатацию или требует масштабирования. Это может быть кластер Elasticsearch, балансировщики nginx или что поинтереснее — распределенная NoSQL СУБД Apache Cassandra.
В материале я расскажу именно об Apache Cassandra: какие ошибки можно совершить при ее использовании, на что стоит обратить внимание и чем лучше не пренебрегать.

Cost reduction - весьма популярное направление, особенно в дни кризиса IT. Вполне естественным является желание оптимизации расходов на “железо” с минимальной потерей производительности, ведь чем больше данных хранится, тем больше может оказаться профит. В данной статье описан кейс эксплуатации Cassandra на HDD дисках как один из способов оптимизации, имеющей смысл при достаточно большом объеме данных.


Я стал большим сторонником DynamoDB за последние несколько лет. Эта база данных имеет много сильных сторон, которых нет у конкурентов, таких как гибкая ценовая модель, соединение без состояния (stateless), которое прекрасно работает для беcсерверных (serverless) вычислений, и постоянное время ответа, даже когда ваша база данных масштабируется до огромных размеров.
Однако разработка структуры данных с помощью DynamoDB вызывает трудности у тех, кто привык к реляционным базам данных, которые доминировали в течение последних нескольких десятилетий. Существует несколько особенностей в создании структуры данных с помощью DynamoDB, но самая значимая - это рекомендация от AWS использовать одну таблицу для всех ваших записей.


Привет, Хабр! Меня зовут Евгений Абрамкин, я руководитель поддержки третьего уровня в направлении омниканальных решений Лиги Цифровой Экономики. Моя команда — последняя «инстанция» во флоу по решению инцидентов. Мы пишем доработки и фиксы, чтобы победить проблему клиента, а еще предоставляем оптимальную конфигурацию для системы, которая передана в эксплуатацию или требует масштабирования. Это может быть кластер Elasticsearch, балансировщики nginx или что поинтереснее — распределенная NoSQL СУБД Apache Cassandra.

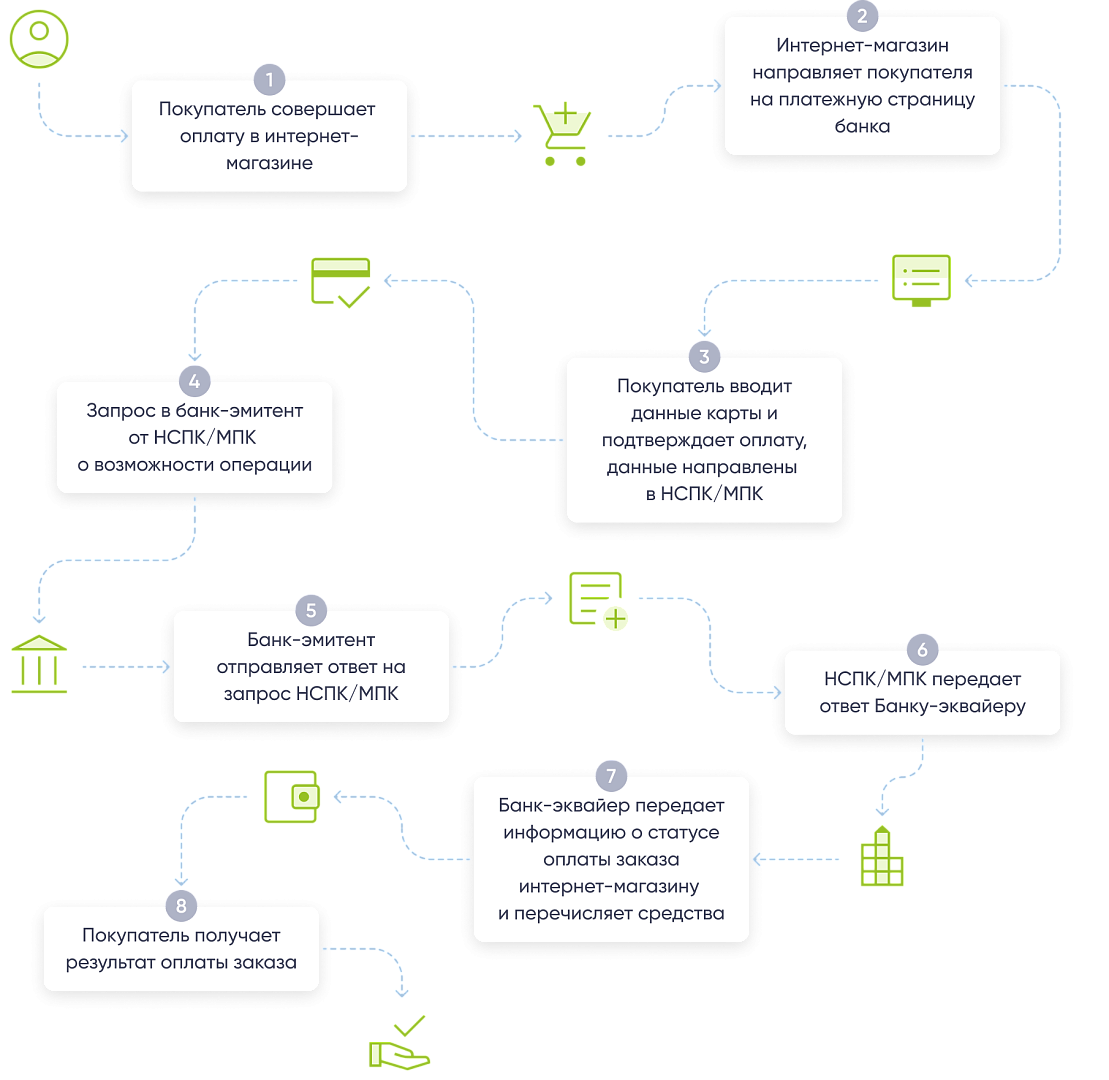
Привет, меня зовут Евгений Думчев, я разработчик в DD Planet. Сегодня хочу поделиться опытом подключения платежного шлюза Сбера, чем мы занимались в рамках одного из проектов. Кажется, это будет полезная история, ведь в нынешние непростые времена многие из нас задумываются о том, чтобы открыть свой «маленький свечной заводик» – какой-нибудь небольшой бизнес на черный день. Тортики там печь, платы паять, в общем, что-нибудь, что бы обеспечило дополнительный доход. Раньше для коммерции подобных сайд-проектов не требовалось ничего, кроме условного Пейпала (к тому же он расширял географию продаж). А теперь волей-неволей приходится задумываться об отечественных решениях для проведения оплат.
Платежный шлюз – как раз такое решение. И оно на самом деле очень простое, любой посетитель Хабра, скорее всего, сможет его развернуть, достаточно хотя бы примерно представлять устройство REST API. В этой статье я расскажу, как подключить и настроить шлюз от Сбера – но в принципе эта инструкция пригодится со шлюзом от любого банка.

Современные технологии позволяют диджитал-потребителям быстро получать доступ к информации, продуктам и услугам. Поэтому компании нуждаются в технологиях обработки данных в режиме реального времени, чтобы оставаться конкурентоспособными и не отставать от своих клиентов.

Несмотря на то, что MongoDB начало движение в сторону строгости реляционной модели, она по прежнему остается документной БД и предполагает возможность сохранения документов произвольной структуры. И при использовании MongoDB в языках с динамической типизацией (JavaScript, Python) сохранение или генерация объектов не вызывает сложностей, поскольку заранее не требуется определить структуру извлекаемого или сохраняемого объекта. Но как действовать в случае использования драйверов для MongoDB для языков со строгой типизацией?
В этой статье мы разберем приемы для работы с неструктурированными данными, которые позволят сохранить преимущества использования сериализации с механизмами рефлексии для извлечения произвольных документов.

Можно ли найти конкретного человека, жившего в XVII веке? Выражаясь современным языком «пробить по базам». Оказывается, архивные документы хранят массу информации об обычных людях того периода. Однако существует ряд сложностей, не позволяющих обычному исследователю добраться до этой информации. Во-первых, нужно пройти определённую процедуру по получению доступа в архив. Во-вторых, не всегда можно выйти на нужный документ, используя так называемый научно-справочный аппарат – различные описи и реестры документов, имеющиеся в архиве. Наконец, не имея навыков чтения документов XVII века, которые написаны скорописью, почти нереально ознакомиться с его содержанием.
Данные проблемы предполагается решить с помощью создания базы данных служилых людей XVII века. Об этом небольшая история.
Как всё начиналось.
Привет! Меня зовут Дмитрий и вот уже более 10 лет я изучаю историю южных уездов России XVII века. Территориально – это современные Белгородская, а также соседние Воронежская, Курская, Липецкая и другие области. Населены они были тогда так называемыми служилыми людьми – они получали здесь в качестве служебного жалования земельные наделы, которые сами и обрабатывали. В XVIII веке их потомки стали однодворцами, а затем государственными крестьянами. Большая часть населения Курской, Воронежской и соседних губерний XIX века происходят из тех самых служилых людей XVI–XVII веков.











Если вы столкнулись с задачей хранения сильно связанных данных, то отличным вариантом будет использовать графовую модель данных. Мы в Текфорс сделали именно так. Почему - разберем в этой статье.

Всем добрый день.
В своей предыдущей статье я уже упомянул о разрабатываемой нами системе, которая решает, казалось бы, не решаемую задачу - а именно автодискавери сетевых элементов в сетях телеком операторов, построение топологий, поиск путей прохождения трафика на основе информации, полученной из самих сетевых элементов. При этом стоит уточнить, что система не нуждается в интеграции со сторонними системами управления, такими как NCE (бывший Huawei u2000 TN), SoEM (СУ Ericsson), Aviat Provision, NFM-P (Nokia), и любыми другими. Т.е. система самодостаточна и способна работать в полностью автономном режиме.
Начну с той проблемы, которая возникла много десятилетий тому назад - и название этой проблемы - актуальная информация о состоянии сетей в режиме он-лайн. Дело в том, что мультисервисные сети давно стали мультивендорными - т.е. в каком-то филиале N любого провайдера связи, с течением времени скопилось множество разновендорного оборудования - сети MEN построены на Cisco, Huawei, Nokia. РРЛ - NEC, Huawei, Nokia и т.д. до бесконечности и в разных последовательностях. И т.к. каждый вендор не стремится создать универсальную СУ, которая могла хотя бы нарисовать топологию мультивендорной сети, приходится изобретать велосипед раз за разом.
Чаще всего велосипеды получались не далеко едущими, одноколесными, неудобными, без сидения или колес. Даже в системах управления крупных вендоров, функциональность не блистала. Более менее вменяемое я увидел в СУ Huawei - NCE. Но опять таки - каждый домен типов оборудования на своих вкладках, и единую топологию не получить - т.е. нельзя отобразить единовременно и на одной подложке сеть MBH (MEN+RRL). Не говоря уже о единовременном отображении специфических проблем, за которыми следят операторы связи - высокая утилизация интерфейсов, BBE/ES/SES/UAS, FCS, RSL Low, QoS Drop по очередям и пр.
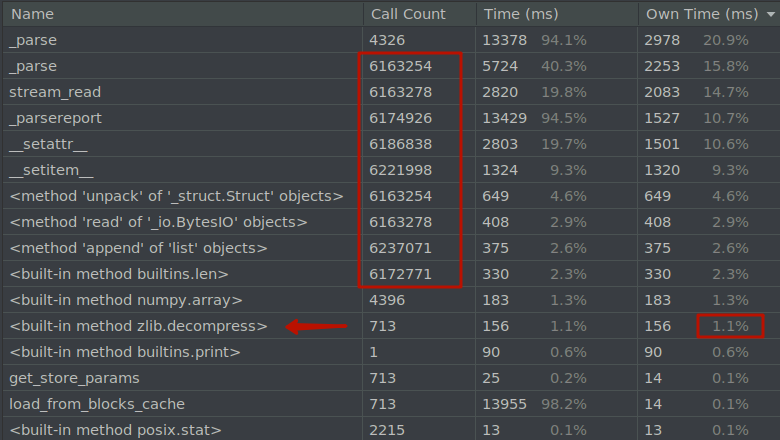
Загрузить миллион записей в питон за секунду?
Нет. Получилось еще быстрее!
У меня есть небольшое хобби - я экспериментирую с машинным обучением применительно к торговле на бирже, в частности, с криптовалютами. После различных наколенных экспериментов я захотел создать удобный инструмент - базу торговых котировок. В процессе работы необходима быстрая загрузка достаточно большого количества данных. Это необходимо для расчетов, генерации данных для обучения, бэк-тестинга и других задач. Количество записей, которые нужно загрузить в питон довольно велико - речь может идти о миллионах и более записей.
В этом материале вы узнаете, как создать Telegram-канал, который будет сам обновляться, получая данные из открытых источников. Используем Python, AWS Lambda, DynamoDB и BeautifulSoup.

Apache Cassandra - это распределенная NoSQL база данных. В этой статье будут описаны основные механизмы передачи, репликации и поддержания согласованности данных внутри сети.

В первой статье из серии об использовании Apache Cassandra в машинном обучении мы обсудили цели и задачи машинного обучения, и поговорили почему Cassandra — превосходный инструмент для обработки больших наборов данных. Также рассмотрели технологический стек, используемый Uber, Facebook и Netflix. Обе статьи основаны на воркшопе Machine Learning with Apache Cassandra and Apache Spark (Машинное обучение с помощью Apache Cassandra и Apache Spark).
В этой статье мы рассмотрим интеграцию Apache Spark с Cassandra и построение эффективных алгоритмов и решений. Мы также обсудим обучение с учителем, без учителя и метрики машинного обучения. Примеры и упражнения доступны на GitHub.

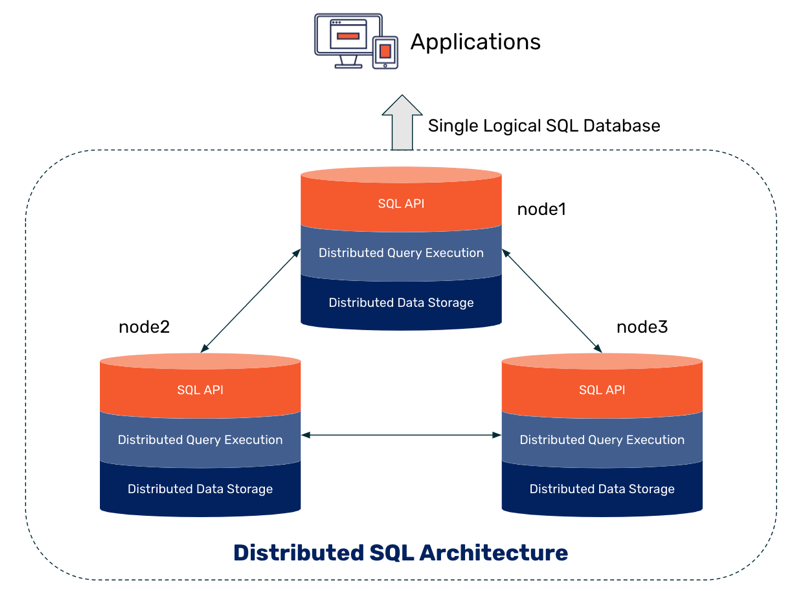
Базы данных (БД) существуют с первых дней программирования, а появились они ещё раньше. Это — неотъемлемые части любых приложений. Хорошо спроектированная БД — это один из важнейших компонентов, влияющих на производительность программных проектов. Из-за этого множество архитекторов программных решений исследовали массу подходов к управлению данными, пытаясь выяснить то, какие из этих подходов работоспособны в определённых сценариях, а какие — нет. Выбор подходящей архитектуры БД обычно сводится к выбору между SQL и NoSQL, между реляционными и нереляционными базами данных. А иногда в одном проекте используют и то, и другое.
В этой статье мы сделаем краткий обзор баз данных, поговорим об их истории, постараемся разобраться с тем, что собой представляют базы данных SQL и NoSQL, выясним ключевые различия между ними.

