Введение
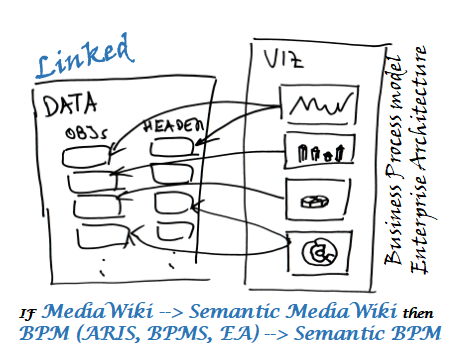
Представление моделей бизнес‑процессов на основе онтологий (онтологическое моделирование) эквивалентно Semantic BPM. Введение в семантический BPM (Business Process Management) см. «Semantic BPM. Семантика и синтаксис бизнес‑процессов» [semBPM24]. Если кратко, то можно провести аналогию: если классическая BPM система (BPMS: ARIS, бизнес‑студия, fox‑manager и т. п.) — это технологический аналог mediawiki (wikipedia), то Semantic BPM — это технологический аналог semantic mediaWiki (Wikidata), т. е.
IF MediaWiki → Semantic MediaWiki then BPM (ARIS, BPMS, EA) → Semantic BPM
Основной замысел (цель) семантического представления процессов (BPM, EA) не классическими BPM‑системами, а семантическими (Linked Data) — такой же, как и у семантических wiki
Одно из ключевых дополнений к wiki‑гиперссылки (html) это указание не просто что «ОбъектА связан с ОбъектомБ» (т. е. просто «связано») и соответствующий кликабельный переход (wiki‑ссылки, markdown syntax), а указание, что «ОбъектА связан с ОбъектомБ» такими‑то типом отношения (впрочем, как и задание других свойств объекта через отношения).
Изначально все BPMS (изначально называемые CASE‑средствами) — семантические, т.к. их суть — это отношения между объектами, только в них семантика глубоко спрятана «под капотом» BPMS и нестандартная (собственная, проприетарная). Semantic BPM «поднимает» семантическую составляющую на поверхность (возможность работы с семантическим слоем) и использует стандартные сематические технологии Linked Data.
В основе RDF (Resource Description Framework) — триплеты «субъект — отношение — объект» лежит ERD: Entity Relationship (ER) diagram. RDF \ ERD — это способ формализации знаний на основе атома знания — триплета. Вообще ER, subject, predicate, типы рассуждений и другие базовые элементы для работы со знаниями в СССР содержались в школьных учебниках [Логика54].