
Исследователи из Чикагского университета представили альтернативный пользовательский интерфейс под названием LipIO. Это контроллер с опцией детекции облизывания губ, который управляет устройствами и движениями в играх с помощью касаний языком.

Вместе с Кириллом Симоновым, ML-разработчиком с экспертизой в компьютерном зрении, разбираемся в принципах работы CV и рассказываем, какие задачи технология решает в медицине.

Всем привет, с вами команда Layer!
Мы рады сообщить, что совсем скоро выйдет наша новая исследовательская работа, посвященная поиску моментов в видео, релевантных пользовательскому запросу. Мы хотим сделать эту работу как можно более доступной для каждого, кто хочет глубже разобраться в теме. Поэтому мы решили написать этот небольшой туториал, посвященный семейству моделей DETR, так как они используются не только для детекции котиков на картинках, но и в таких необычных доменах, как детекция моментов в видео. Мы уверены, что среди читателей многие знакомы с основами DETR, однако подозреваем, что не все могли следить за её развитием. Всё‑таки по сравнению с YOLO, DETRу пиара явно не достает. В этой статье мы предлагаем краткий обзор эволюции модели, чтобы помочь вам лучше ориентироваться в новых исследованиях. Если же вы впервые слышите о DETR или хотите освежить свои знания, то бегом читать — тык, если после прочтения остались вопросы, то можно ознакомиться с этими видео — тык, тык.
Давайте детальнее разберёмся, что ждёт вас в этом туториале. Сначала мы рассмотрим недостатки оригинальной версии DETR, а затем перейдём к архитектурным улучшениям, которые либо устранили эти проблемы, либо заметно их сгладили. Начнём с Deformable DETR — модели, которая оптимизировала вычисления. Затем обратим внимание на Conditional DETR и DAB DETR — архитектуры, которые существенно переосмыслили роль queries в модели. Далее мы погрузимся в особенности DN‑DETR, который стабилизирует one‑to‑one matching. После этого детально разберём DINO DETR — модель, которая объединяет и улучшает идеи DN‑DETR и DAB‑DETR, а также переизобретает RPN для детекционных трансформеров. И в завершение нашего путешествия мы познакомимся с CO‑DETR, который объединил классические детекторы, такие как ATSS, Faster RCNN, и модели типа DETR, установив новые SOTA метрики на COCO.

Ещё 10–20 лет назад многие думали, что роботы под управлением искусственного интеллекта возьмут на себя всю тяжёлую и опасную работу на предприятиях. Однако нейросети нашли применение в офисах, колл‑центрах, службе поддержки и даже стали полезны людям из творческих профессий — копирайтерам, дизайнерам, программистам. Тем не менее создание роботов, которые могут самостоятельно выполнять сложные физические манипуляции с материальными объектами, остаётся трудной и нерешённой задачей.
В этой статье я расскажу, как команда ML R&D в отделе робототехники Маркета создаёт роборуку и обучает нейросети, благодаря которым робот взаимодействует с физическим миром.
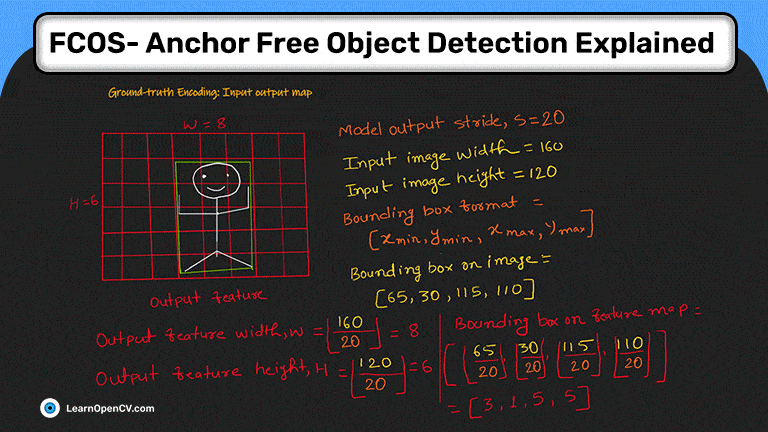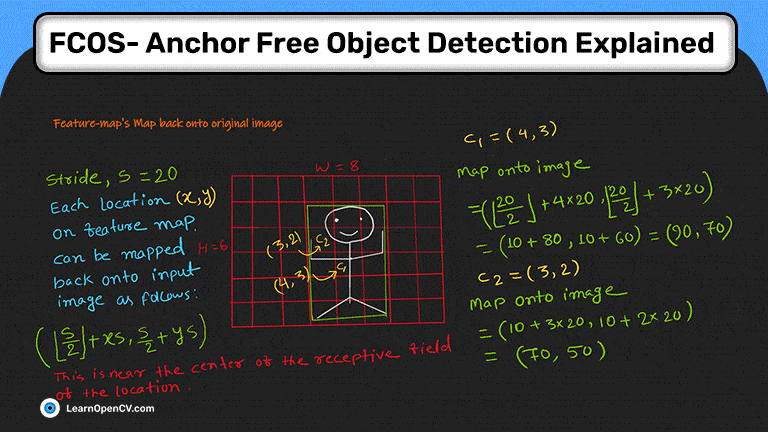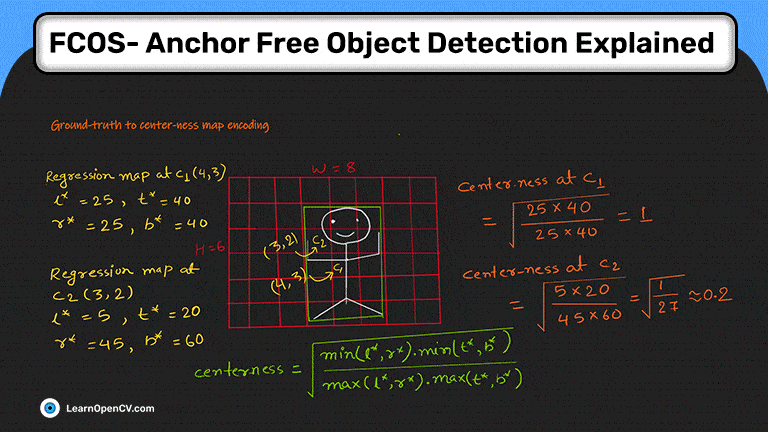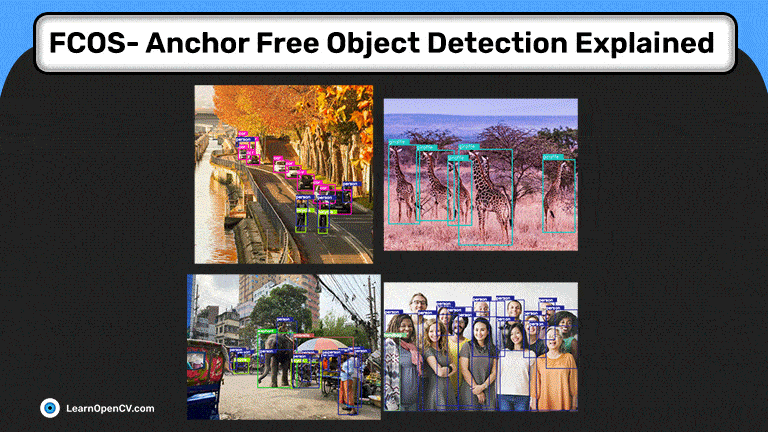
FCOS: полностью сверточное одноступенчатое обнаружение объектов - это детектор объектов без привязки. Он решает проблемы обнаружения объектов с помощью метода прогнозирования по пикселям, аналогичного сегментации. Большинство последних детекторов объектов без привязки или без привязки на основе глубокого обучения используют FCOS в качестве основы.

Рассмотрим библиотеку PyCUDA, как альтернативу CUDA для C/C++. Оценим её возможности и проведем сравнение производительности на конкретном примере, а именно реализуем алгоритм Харриса для детекции углов на изображении.
Осенью мы с друзьями участвовали в хакатоне DIGITAL SUPERHERO от организаторов хакатона ИТС и СЦ, о котором я писал в статье. Хакатон проходил с 18 по 23 сентября 2020 года. Мы выбрали задачу Распознавание аномалий (объектов и инцидентов) на фотоматериалах, полученных с беспилотных летательных аппаратов (БПЛА) в треке "Разработка алгоритмов распознавания. В рамках кейса нужно было разработать алгоритм по автоматическому выявлению аномалий на изображении и разработать веб-интерфейс для загрузки и разметки изображений. В этой статье я бы хотел рассказать о нашем решении для детекции аномалий с помощью модели YOLOv5 в виде практического туториала. Кому интересно, прошу под кат.

Популярность нейронных сетей резко взлетела вверх и падать не собирается. На этой волне хайпа их пытаются применить везде, где есть большие данные. И даже там, где реальных больших данных нет, их порой создают - генерируют. В итоге мы имеем большое многообразие задач, в которых свои инструменты и подходы, и в наших 20 лекциях мы постарались затронуть наиболее интересные из них. Эти лекции не для начинающих, нет. Для начинающих у Samsung есть курсы по нейронным сетям, с них и можно начинать. AI-лекторий Samsung Innovation Campus - для тех, кто разобравшись с основами, захочет узнать больше.
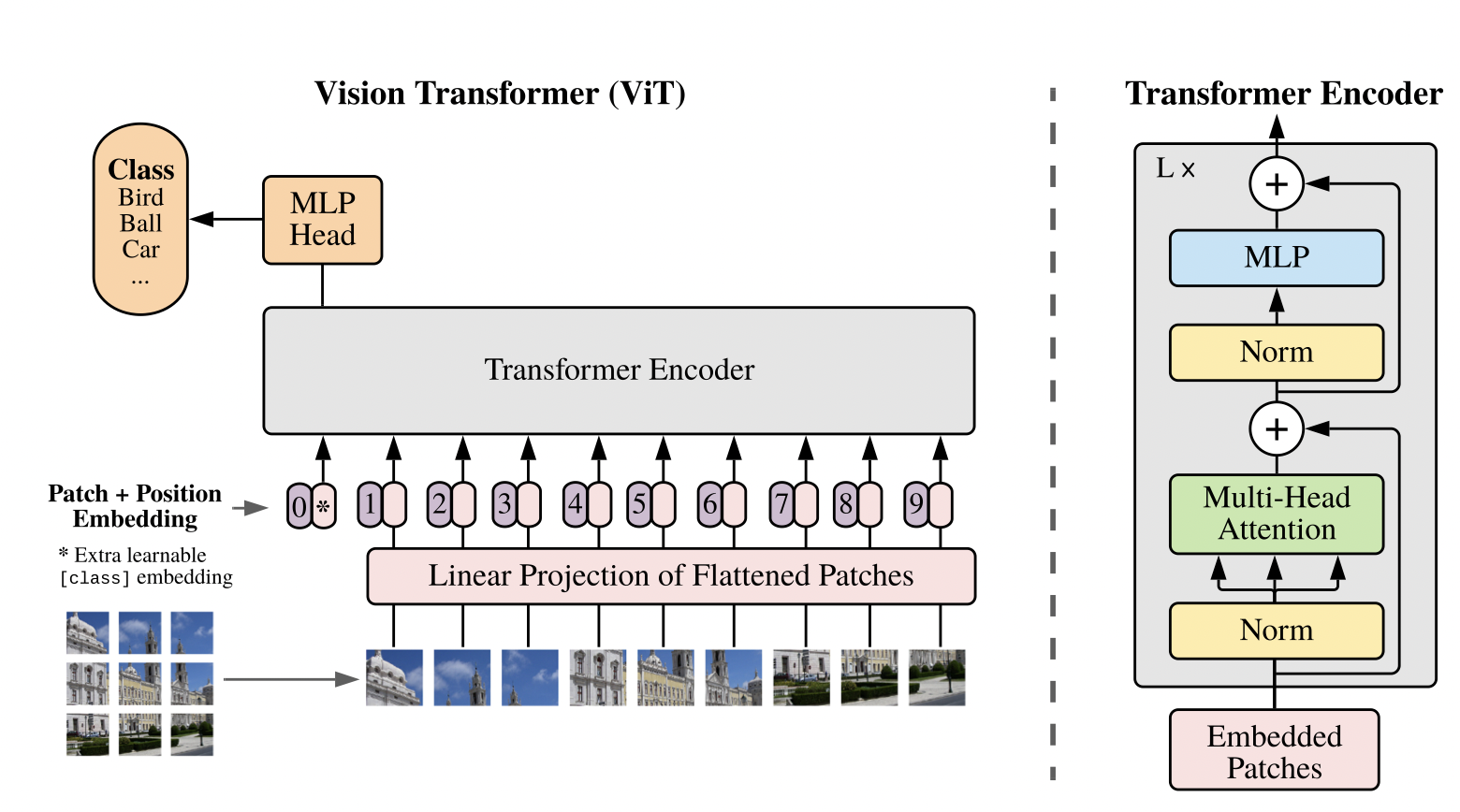
Прошедший 2021-й год ознаменовался настоящей революцией в области компьютерного зрения.
Трансформеры, подобно новым штамма Ковида, вытеснившие конкурентов в области обработки естественного языка (NLP) и задачах, связанных с обработкой звука, добрались и до компьютерного зрения.
Сверточные сети, чье место на Олимпе в различных бенчмарках компьютерного зрения и первые места в топах на PapersWithCode казались незыблемы (в том смысле, что против лома нет приема, если нет другого лома) были сброшены с них рядом архитектур частично или полностью основанных на механизме внимания.
В данном обзоре я хотел бы рассказать о нескольких самых ярких прорывах и идеях в совершенствовании архитектур и обучении ViT-ов (Visual Transformers).

В этой статье будет описан подход (идея), как при помощи детектирующей нейросети решать более сложные задачи, чем детекция. Идея, лежащая в основе: давайте решать не задачу детекции объекта, а задачу детекции ситуации. Причем, вместо того, чтобы конструировать новую нейросетевую архитектуру, мы будем конструировать входящий кадр. А решать саму задачу будем при помощи стандартных предобученных сетей.
В качестве детектирующей нейросети использована архитектура YOLO, и все гипотезы этого подхода проверены для неё. Вероятно, эти же подходы будут работать и на других архитектурах. Действительно ли они будут работать, надо проверять отдельно.
В заметке я покажу как «переформулировать» задачу детекции так, чтобы решать другие, более сложные задачи. А именно, при помощи YOLO можно не только решать задачу детекции, но и задачу трекинга. И даже больше.

Кто такой детектор?
Данная статья посвящена постановке задачи детекции и обзору первых двухстадийных детекторов, таких как: R-CNN, Fast R-CNN и Faster RCNN.

Кто такой YOLO? 🤔
Когда пытаешься разобраться в работе YOLO по статьям в интернете, постоянно натыкаешься на примерно такое объяснение: «Алгоритм делит изображение сеткой SxS, где каждому элементу этой сетки соответствует N ббоксов с координатами, предсказаниями классов и тд...». Но лично мне становилось только непонятнее от такого высокоуровнего описания.. Ведь в исследованиях часто всё происходит примерно так: перебирают гипотезы, пока не получат приемлемый результат, а потом уже придумывают красивое описание. Поэтому для ясности хочется в данной статье рассказать, как вообще приходили к идеям, которые ложились в основу YOLOv1 и последующих версий.

Всем доброго дня. Совсем недавно я закончила продвинутый курс от Deep Lerning. Курс объемный, много свежей информации. Мне, как закончившей прикладную математику и часто по работе соприкасающейся с искусственным интеллектом (нейросетки, генетика, fuzzy logics) было не сильно сложно, но мега-увлекательно за счет того, что ребята очень заинтересованные и рассказывали про свежие интересные модели, еще и на русском языке. Приятно видеть, что ИИ-сфера в нашей стране тоже не стоит на месте.
Хотелось сделать своими руками что-нибудь эдакое полезное и одновременно мега-современное и вот что я придумала. У нас есть частный дом, там есть дворовые коты, которых надо кормить и в мое отсутствие. А так же есть еще птицы, кроты, чужие вездесущие собаки и другая живность, которых не стоит кормить, если не хотим, чтобы они у нас все поселились. Так вот, а что, если прикрутить модель детекции изображений к умной кормушке? Далее было бы здорово научиться использовать голосовые команды, например, на закрытие кормушки. И чтобы не писать никаких специальных программ, воспользуемся телеграмм-ботами, телеграмм стоит почти в каждом телефоне.
В данной статье я сделала акцент именно на том, как пользоваться моделями детекции изображений на практике.

В этой статье мы попытаемся рассказать про трансформерную архитектуру VIT и предысторию его формирования. Сегодня не совсем понятно, почему этот "формат" нейронок настолько эффективен. Некоторые говорят механизм внимания, но некоторые практики делают больше ставок в области Computer Vision на MetaFormer. https://github.com/sail-sg/poolformer
Нейросети остаются для нас “теневым” процессом, подобным черному ящику. И изучение Deep Learning уже напоминает больше не математику, а биологию, где мы следим за поведением нашего детища.


YOLO расшифровывается как You Only Look Once. Это широко известная архитектура компьютерного зрения, которая знаменита в том числе своим огромным количеством версий: первая из них вышла в 2016 году и решала только задачу детекции объектов на изображении, а последняя – одиннадцатая – появилась в сентябре этого года и уже представляет из себя целую фундаментальную модель, которую можно использовать для классификации, трекинга объектов на видео, задач pose estimation и тд. Все это – в реальном времени.
Да, за 8 лет своего существования YOLO стала своеобразным трансформером во вселенной компьютерного зрения: ее любят и используют повсеместно.
Эта статья – полноценная техно-история YOLO. Мы расскажем, что представляет из себя задача детекции, как работала самая первая YOLO и как ее дорабатывали во всех последующих версиях.

Привет, Хабр! Меня зовут Владислав, я CV Engineer в компании YADRO. В этой статье я расскажу, как мы разрабатывали и обучали алгоритм детекции документов для нашего планшета Kvadra_T. Я подробно описал нюансы задачи и весь наш путь — от классического подхода до генерации недостающих датасетов и обучения на них нашей собственной нейросети. Постарался сделать историю интересной как для новичков в теме, так и для более опытных читателей. Режим детекции, кстати, уже доступен в kvadraOS.

Детекция объектов в реальном времени является важнейшей задачей и охватывает большое количество областей, таких как беспилотные транспортные средства, робототехника, видеонаблюдение, дополненная реальность и многие другие. Сейчас такая задача решается с помощью двух типов алгоритмов: one-step алгоритм детекции, например You Only Look Once (YOLO), и two-steps алгоритм, например Faster Region-Based Convolutional Neural Network (Faster R-CNN). Двухстадийный подход имеет ряд недостатков: долгое обучение и инференс, плохое качество детекции маленьких объектов, неустойчивость к различным размерам входных данных. Одностадийный алгоритм детекции подразумевает одновременное выполнение детекции и классификации, что обеспечивает end-to-end обучение с сохранением высоких показателей как точности, так и скорости.
