Недавно мы рассказывали про генератор стихов. Одной из особенностей языковой модели, лежащей в его основе, было использование морфологической разметки для получения лучшей согласованности между словами. Однако же у использованной морфоразметки был один фатальный недостаток: она была получена с помощью “закрытой” модели, недоступной для общего использования. Если точнее, выборка, на которой мы обучались, была размечена моделью, созданной для Диалога-2017 и основанной на закрытых технологиях и словарях ABBYY.
Мне очень хотелось избавить генератор от подобных ограничений. Для этого нужно было построить собственный морфологический анализатор. Сначала я делал его частью генератора, но в итоге он вылился в отдельный проект, который, очевидно, может быть использован не только для генерации стихов.
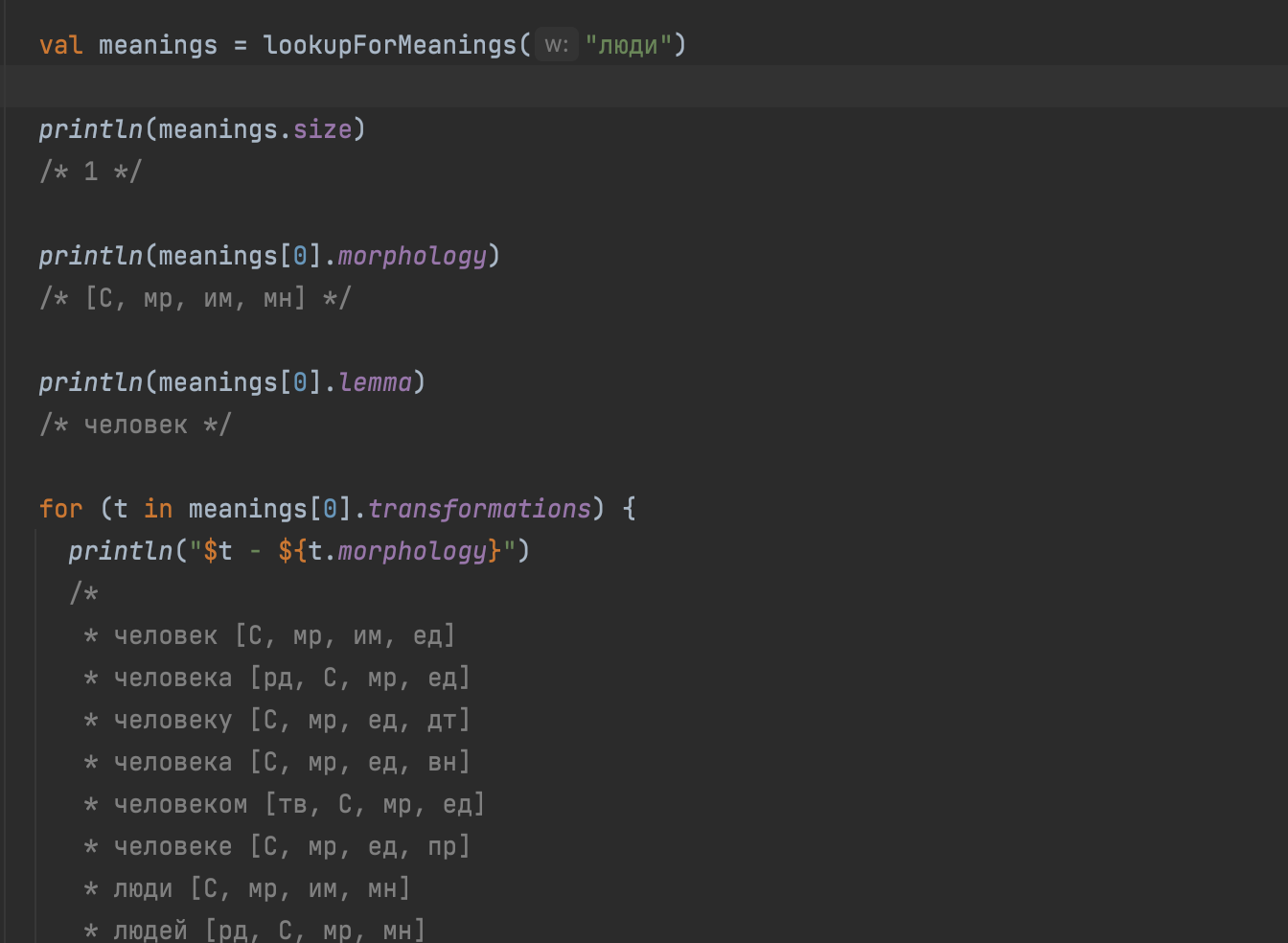
Вместо морфологического движка ABBYY я использовал широко известный pymorphy2. Что в итоге получилось? Спойлер — получилось неплохо.