Продолжаем цикл статей про DMP и технологический стек компании Targetix.
На это раз речь пойдет о применении в нашей практике Apache Spark и инструментe, позволяющем создавать ремаркетинговые аудитории.
Именно благодаря этому инструменту, однажды посмотрев лобзик, вы будете видеть его во всех уголках интернета до конца своей жизни.
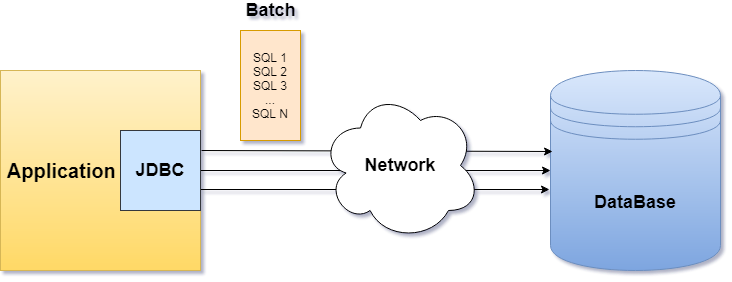
Здесь мы и набили первые шишки в обращении с Apache Spark.
Архитектура и Spark-код под катом.

На это раз речь пойдет о применении в нашей практике Apache Spark и инструментe, позволяющем создавать ремаркетинговые аудитории.
Именно благодаря этому инструменту, однажды посмотрев лобзик, вы будете видеть его во всех уголках интернета до конца своей жизни.
Здесь мы и набили первые шишки в обращении с Apache Spark.
Архитектура и Spark-код под катом.