
Читать далее

Исследователь из Wiz Research под ником Nagli подробно рассказал, какие именно действия выполнялись в рамках пентеста сетевых ресурсов DeepSeek, когда в IT-инфраструктуре китайской компании была обнаружена открытая аналитическая база данных ClickHouse, содержащая, вероятно, тестовую информацию.
Рынок отечественной информационной безопасности штормит: вал кибератак (их интенсивность увеличилась в десятки раз), уход зарубежных вендоров, необходимость поиска и создания отечественных альтернатив.
27 апреля Positive Technologies приглашает вcех желающих на встречу разработчиков.

Распределенная система управления базами данных ClickHouse от Яндекса впервые оказалась в топ-50 самых популярных в мире СУБД по версии DB-Engines Ranking. ClickHouse расположилась на 49-й строчке рейтинга.

На нашем митапе 27 июня расскажем, как мы в кратчайшие сроки нашли и внедрили альтернативное решение для предоставления клиентской аналитики в режиме реального времени на базе open-source технологий Clickhouse и Redis.


20 сентября 2021 года «Яндекс» с партнерами объявил о создании компании ClickHouse Inc.. Спустя всего 2 месяца она уже привлекла $250 млн инвестиций, получив оценку капитализации в $2 млрд. Это сделало ее так называемым «единорогом» — частной компанией, стартапом, оцениваемым в $1 млрд и выше. Впервые этот термин был использован в 2013 году известным венчурным предпринимателем, основателем Cowboy Ventures Айлин Ли, выбравшей это мифическое животное как яркий образ для представления статистической редкости таких успешных компаний.
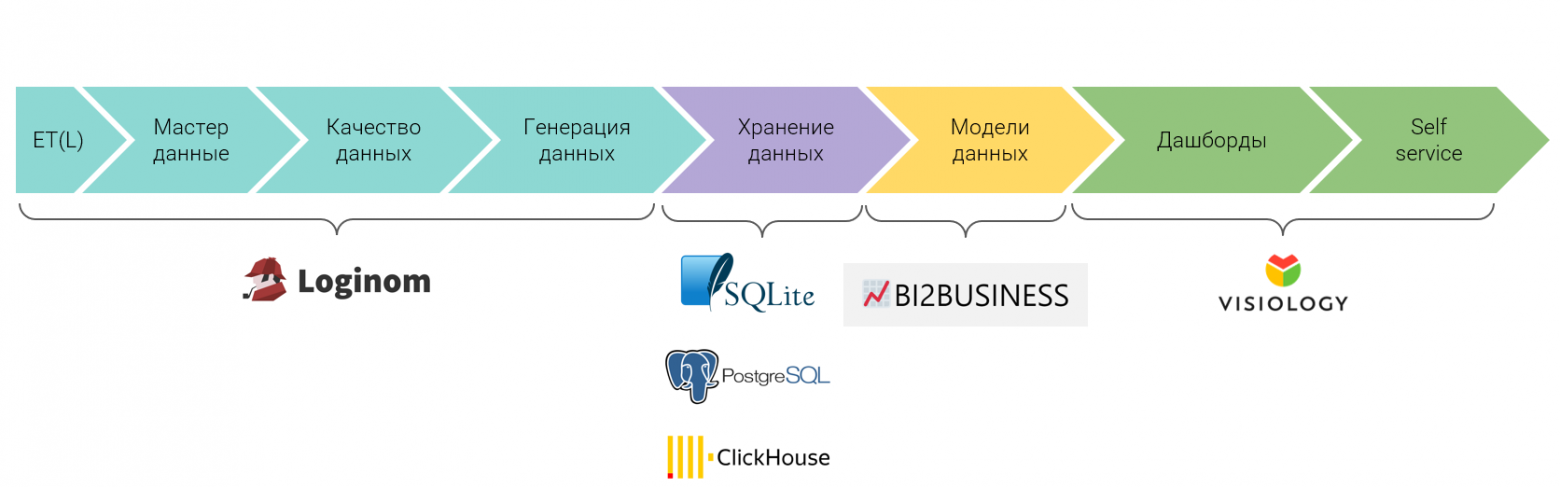
Консультанты BI2BUSINESS, реализовавшие десятки успешных проектов в сфере бизнес-аналитики на платформе Qlik Sense за последние 9 лет, представили новую концепцию BI-платформы на основе российских продуктов и OpenSource-решений. По заявлениям экспертов компании, добиться столь же эффективной работы BI и упростить внедрение бизнес-аналитики сегодня можно и без зарубежных решений. Новая концепция включает в себя специально разработанную методику внедрения и организации данных, а также лучшие в своем роде из российских решений — средства сбора и обработки информации Loginom, а также инструментарий для визуализации с элементами self-service Visiology.

Вышел Jaeger v2. Новая версия популярной платформы для распределённой трассировки теперь включает поддержку OpenTelemetry в основе, что значительно улучшает производительность и упрощает развёртывание.

6 и 7 августа приглашаем бэкенд-разработчиков на Weekend Offer. За выходные вы сможете пройти все собеседования. Если всё сложится удачно, сразу же позовём вас в команду VK Мессенджера.
Эта новость — о двух Open Source-решениях с непростой судьбой: clickhouse-exporter и clickhouse_fdw. Именно открытость и сила сообщества помогли им выжить, несмотря на перипетии судьбы (смену разработчиков).
Нам же они были важны, поскольку оба используются в проектах, а недавно появился запрос на актуализацию их версий. Так на Docker Hub появились два новых образа: clickhouse-exporter и spilo (включает в себя clickhouse_fdw). Они могут пригодиться тем, кто работает с ClickHouse в Docker или Kubernetes.
Облачная платформа Yandex Cloud заявила о расширении программы обучения по хранению и обработке данных в облаке. В программе появились несколько курсов, включая курс для дата‑инженеров и дата‑аналитиков по работе с базой данных ClickHouse, представленной на платформе в виде управляемого сервиса. Обучение доступно на платформе «Яндекс Практикум», самостоятельно нужно оплатить только ресурсы облачной платформы для выполнения практических заданий
Привет, Хабр
Однажды команда LogDoc, которая тогда ещё была просто дружеской компанией суровых разработчиков, после бурного обсуждения очередного напряжённого рабочего дня вынесла однозначный вердикт — в мире нет и не предвидится нормального, человеческого продукта для работы в распределённой среде с логами, трейсами, сигналами и прочим подобным. Нас это опечалило (по очевидным причинам) и воодушевило — мы увидели возможность создать полезный продукт. Подумали, собрались с духом и выложились полностью в попытке реализовать задуманное. Именно результат наших усилий мы представляем вам в этой вводной статье.


Приветствуем!
На связи Глеб Кононенко и Алексей Диков, мы разработчики из Лиги Цифровой Экономики. Год назад на одном большом проекте мы с коллегами начали работать с ClickHouse и сразу столкнулись с кучей проблем и недостатком информации по их преодолению.
ClickHouse — это специфичная, очень быстрая база данных. Особенность заключается в том, как хранятся и обрабатываются данные. Для каждой таблицы указывается Engine, движок, который обрабатывает данные после загрузки в асинхронном режиме. Обработка позволяет удалять дубликаты, сортировать данные, реплицировать и т. д. Более подробно с разными движками можно ознакомиться здесь.
Продукт — с открытым исходным кодом, русскоязычной документацией и возможной поддержкой. Поэтому растущая популярность неудивительна.
Мы набрались опыта, «набив шишки» на практике, и готовы им поделиться — запускаем цикл статей о том, как правильно «готовить» ClickHouse. И начнем с того, как эффективно создавать и использовать распределенные таблицы.
Немного о проекте:

Сказ о том, нормализация данных завела производительность many-to-many в postgres в тупик, как это зло было повержено, и как тут нам помог Clickhouse.
Порой бывают ситуации, когда стоит посмотреть на задачу будто с нуля и отбросить предыдущий опыт и best practices. Подумать на несколько шагов вперёд. И лучше до того, когда уже вышли из SLA или нахватали негатива от клиентов или бизнеса. Об одной такой задаче и стандартном решении, которое пришлось больно редизайнить, хочется и поделиться с сообществом в этой статье.

Привет, Хабр! Меня зовут Никита Ильин, я занимаюсь разработкой архитектуры BI-платформы Visiology. Сегодня мы поговорим про оптимизацию ClickHouse — ведущей СУБД, которую все чаще используют для решения задач аналитики на больших объемах данных. В этой статье я расскажу, почему важно оптимизировать ClickHouse, в каких направлениях это можно делать, и почему разумный подход к размещению информации, кэшированию и индексированию особенно важен с точки зрения производительности BI-платформы. Также мы поговорим о том, к каким нюансам нужно готовиться, если вы решаете оптимизировать CH самостоятельно, сколько времени и сил может потребовать этот процесс и почему мы решили “зашить” в новый движок ViQube 2 десятки алгоритмов автоматической оптимизации.

Около двух лет назад вышла небольшая статья Kafka Streams — непростая жизнь в production, в которой я описывал сложности, с которыми наша команда столкнулась при попытке решить задачи проекта с помощью kafka-streams. Эксперимент вышел неудачным, и мы в итоге совсем отказались от этой технологии. Вместо нее решили попробовать Clickhouse (CH), и сейчас уже можно сказать, что эта база нам очень хорошо подошла и отлично решает почти все задачи, которые нам ставит бизнес. В этой статье я расскажу об особенностях использования CH.
В этой статье хотелось бы рассмотреть такой вопрос - как частичное обновление больших объемов данных в таблицах, которые активно используются пользователями на чтение. Задача является типовой, и с ней сталкивается каждый инженер данных. При этом не важно на какой ступеньке своей карьерной лестницы вы находитесь, Junior или Senior, такие задачи будут.

На одном крупном проекте мы, инженеры компании «Инфосистемы Джет», столкнулись с типичной проблемой стандартных инсталляций Zabbix на больших объемах - производительностью и низкой отказоустойчивостью базы данных. Конфигурация Zabbix была следующей:
• один Zabbix-сервер;
• множество прокси;
• сервер БД PostgreSQL с расширением TimescaleDB;
• сервер Grafana для визуализации данных.
При обычной нагрузке (12000 NVPS) система работала стабильно, но стоило произойти массовой аварии на инфраструктуре или перезагрузке сервера/прокси, как производительности БД не хватало. В такие моменты очень быстро накапливались очереди обработки данных, заканчивались кэши – система фактически прекращала работу. Непростую ситуацию ухудшали еще ложные срабатывания (данные не всегда могли попасть в БД) и рассылка уведомлений ответственным администраторам, проверявшим состояние систем в WEB-интерфейсе. Для восстановления работы приходилось перезапускать компоненты друг за другом, контролируя нагрузку на БД.
Проблему оперативно решили при помощи снижения количества чанков для хранения трендов. Причина происходящего крылась в некорректном партиционировании трендовых данных. Детально о проблеме и методах решения можно почитать в баг-репорте производителя (ZBX-16347). Он помог нам в устранении аварии, но ограничиваться только им не стали – одного репорта, на наш взгляд, было недостаточно. Мы стали смотреть шире и задумались над альтернативными решениями.
А какие варианты есть?
Начнём с того, что наибольшая нагрузка на БД в Zabbix создается на операциях с историческими данными и происходящими в мониторинге событиями. Это таблицы: history, history_uint, history_text, history_str, history_log, events, problems. Производитель предлагает использовать следующие БД: MySQL, PostgreSQL и Oracle DB. Кроме того, исторические данные можно отправлять и в Elasticsearch.