В один из будничных дней, под вечер, от моего начальника прилетела интересная задачка. Прилетает
ссылка с текстом: «хочу отсюда получить все, но есть нюанс». Через 2 часа расскажешь, какие есть мысли по решению задачи. Время 16:00.
Как раз об этом нюансе и будет эта статья.
Я как обычно запускаю selenium, и после первого перехода по ссылке, где лежит искомая таблица с результатами выборов Республики Татарстан, вылетает оно
Как вы поняли, нюанс заключается в том, что после каждого перехода по ссылке появляется капча.
Проанализировав структуру сайта, было выяснено, что количество ссылок достигает порядка 30 тысяч.
Мне ничего не оставалось делать, как поискать на просторах интернета способы распознавания капчи. Нашел один
сервис
+ Капчу распознают 100%, так же, как человек
— Среднее время распознавания 9 сек, что очень долго, так как у нас порядка 30 тысяч различных ссылок, по которым нам надо перейти и распознать капчу.
Я сразу же отказался от этой идеи. После нескольких попыток получить капчу, заметил, что она особо не меняется, все те же черные цифры на зеленом фоне.
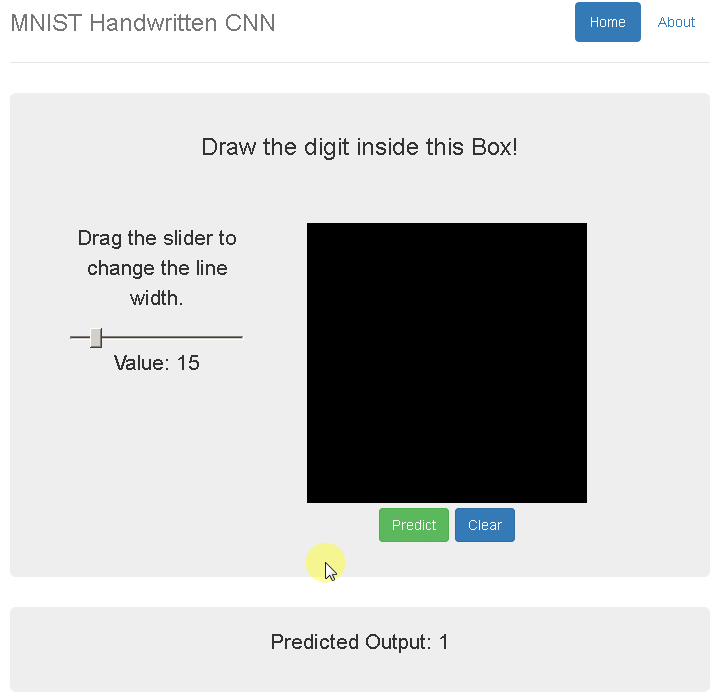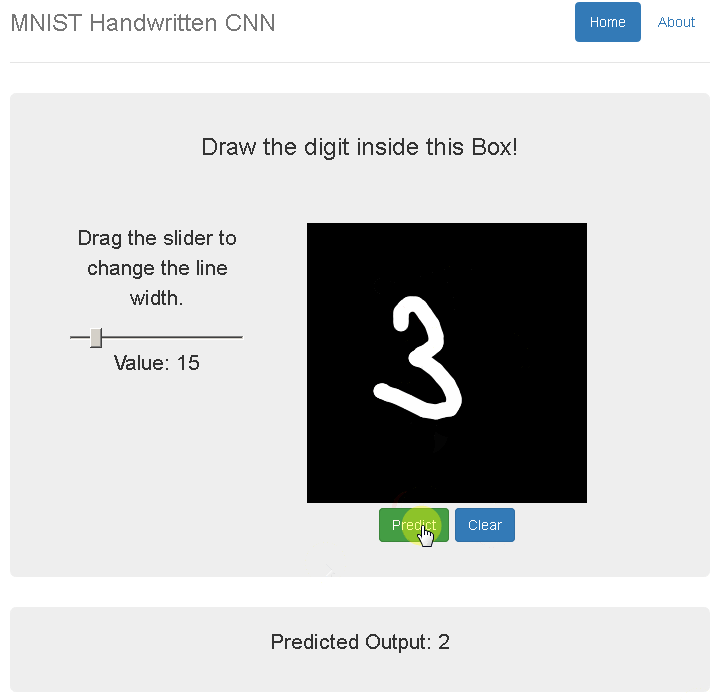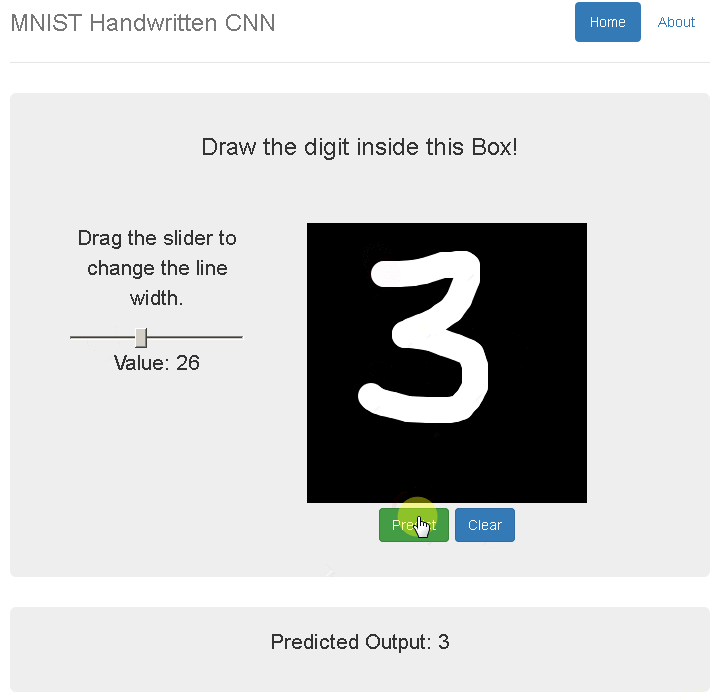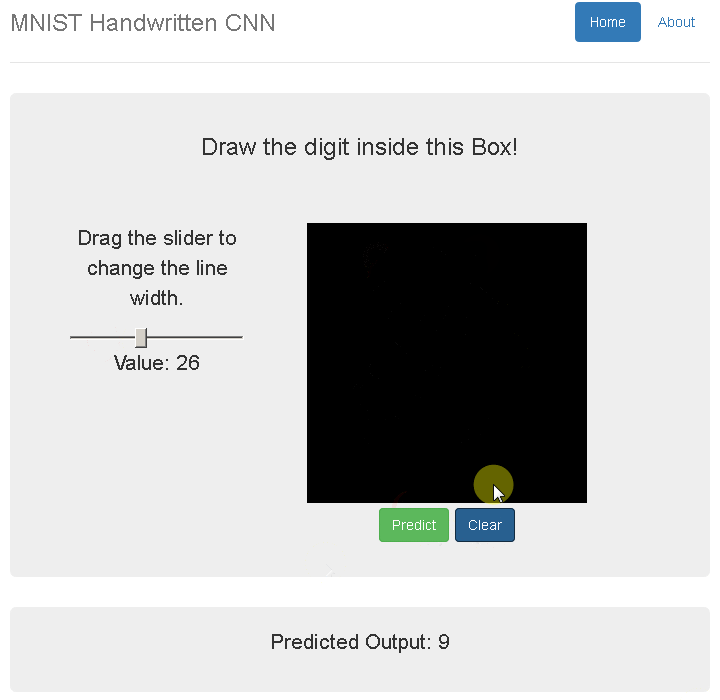
А так как я давно хотел потрогать «компьютер вижн» руками, решил, что мне выпал отличный шанс попробовать всеми любимую задачу MNIST самому.
На часах уже было 17:00, и я начал искать предобученные модели по распознаванию чисел. После проверки их на данной капче точность меня не удовлетворила — ну что ж, пора собирать картинки и обучать свою нейросетку.
Для начала нужно собрать обучающую выборку.
Открываю вебдрайвер Хрома и скриню 1000 капчей себе в папку.