
Стартап Black Forest Labs объявил о своём формировании и немедленно представил три модели для генерации изображений по текстовому промпту. Выходцы из Stability AI создали модели, которые претендуют на звание лучших в индустрии.
Стартап Black Forest Labs объявил о своём формировании и немедленно представил три модели для генерации изображений по текстовому промпту. Выходцы из Stability AI создали модели, которые претендуют на звание лучших в индустрии.

AMD представила бета-версию инструмента Amuse 2.0, позволяющего локально запускать модели Stable Diffusion для генерации изображений. С её помощью пользователи могут полностью контролировать параметры генерации, но для работы нужны процессоры серии AMD Ryzen AI или графические ускорители Radeon RX 7000.

Всем привет!
Я к вам с неожиданной новостью: «Intel инвестировала 50 миллионов долларов в Stability AI — разработчика нейросети Stable Diffusion».
Раунд финансирования закрылся в октябре, новостей про это практически нет, хотя есть что обсудить ведь это сулит нам интересные перспективы.
Я, как известный интернет эксперт в области ВСЕГО ?, просто обязан высказать своё личное мнение и рассказать, к чему нас это может привести.

Разработчик Дивам Гупта (Divam Gupta) выпустил приложение Diffusion Bee, генерирующее изображения по текстовому описанию на базе модели Stable Diffusion. Приложение работает локально и не требует подключения к Сети. Важно отметить, что пока доступна версия только для Mac на базе чипов Apple Silicon.

Stability AI представила версию DreamStudio с открытым исходным кодом. Это интерфейс для модели генератора изображений Stable Diffusion.


Разработчики открытой модели машинного обучения Stable Diffusion представили Stable Video Diffusion — решение для генерации коротких видео. Организация обновила GitHub-репозиторий и опубликовала материалы исследования.

Инженер Бьёрн Карманн (Bjørn Karmann) из Амстердама представил промт-камеру Paragraphica без объектива и привычных механизмов для фотооборудования. Вместо всего этого устройство генерирует изображение на основе данных о местоположении.
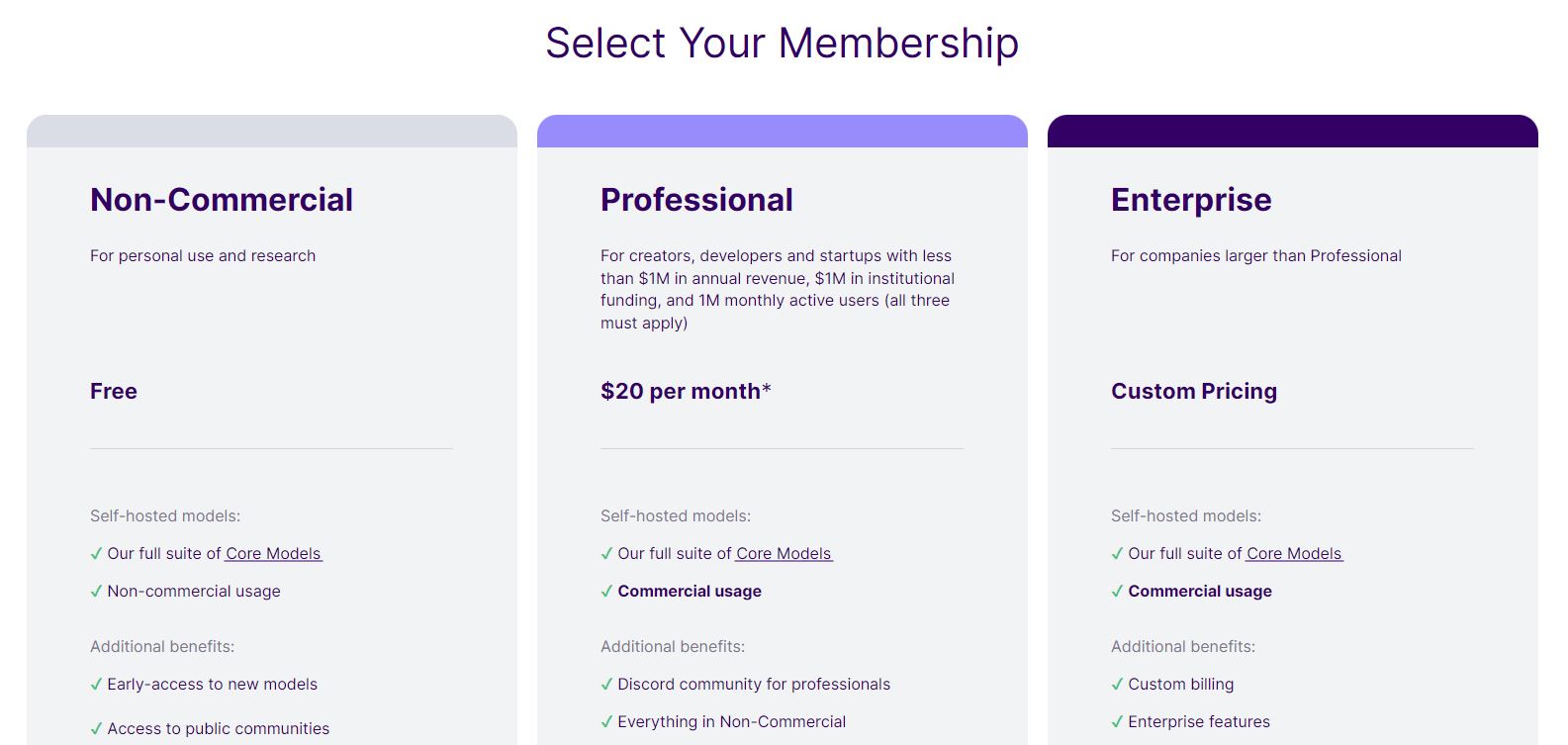
Stability AI, создатель модели преобразования текста в изображение Stable Diffusion, теперь предлагает услугу подписки, которая стандартизирует способы использования её ИИ в коммерческих целях.

В веб-редакторе изображений Canva появилась функция генерации картинок по текстовому описанию. Функция построена на базе Stable Diffusion и доступна бесплатно в ограниченном режиме.

Stability AI сообщила о выпуске модели машинного обучения для генерации изображений Stable Diffusion 2.0. Компания улучшила качество и повысила вариативность получаемых изображений.

В рамках проекта Riffusion разработчики развивают вариант системы машинного обучения Stable Diffusion для генерации музыки вместо изображений. Мелодии можно создавать как на основе предложенного шаблона, так и с помощью текстового описания на естественном языке.

Компания Qualcomm представила платформу AI Hub с библиотекой из 75 оптимизированных ИИ-моделей. С её помощью разработчики смогут внедрять ИИ-функции в приложения для устройств на базе Snapdragon и других чипов. Платформа будет доступна на Hugging Face и GitHub.
AI Hub открывает доступ к таким моделям, как Stable Diffusion, Whisper, ControlNet и 72 другим.

Друзья, всем привет! Сегодня я расскажу вам о новом чуде технологий от ребят из OpenAI. Знакомьтесь — Sora, искусственный интеллект, который умеет делать видео по вашему текстовому описанию. Да-да, вы не ослышались: напишите ему, что вы хотите видеть, и он это создаст. Волшебство? Почти. Давайте разбираться, что за зверь такой этот Sora и почему это круто. Ведь все видео в этой статье сделаны с помощью искусственного интеллекта.
Много видео роликов в статье.

Всем привет, вчера обновился Automatic 1111 - самый популярный интерфейс для генерации изображений с помощью нейросетей Stable Diffusion. Посмотрим что нового!
Внизу будет полный чейнджлог который я постарался аккуратно перевести, но сперва я расскажу вам о самых заметных и приятных нововведениях, их не много, но они действительно крутые!

Три художника подали коллективный иск против нейросетей Stability AI, Deviant Art и Midjourney. Авторы иска утверждают, что ИИ нарушает законы об авторском праве с помощью инструмента для преобразования текста в изображение Stable Diffusion.

Midjourney запретила сотрудникам Stability AI использовать свой сервис, обвинив их в провоцировании сбоев в работе системы в начале этого месяца при попытке собрать данные.

Разработчики Apple оптимизировали Stable Diffusion для работы с проприетарным фреймворком Core ML. Теперь нейросеть можно использовать с максимальной производительностью на устройствах на базе процессоров Apple Silicon и под управлением iPadOS 16 и macOS Ventura.

Диффузионные нейросети, такие как DALL-E 2, Imagen и Stable Diffusion, запоминают отдельные изображения из обучающих данных и выдают их во время генерации, выяснили исследователи. Препринт научной статьи опубликован на портале arXiv. Как показала работа авторов, диффузионные нейросети гораздо менее приватны, чем предыдущие генеративные модели, такие как GaN. Для устранения уязвимостей могут потребоваться новые достижения в обучении с сохранением конфиденциальности.

Stability AI объявила о выпуске Stable Diffusion XL 1.0, «самой продвинутой» модели преобразования текста в изображение. Она обеспечивает «более яркие» и «точные» цвета и лучшую контрастность, тени и освещение по сравнению со своим предшественником.